Salesforce Research Introduces AgentOhana: A Comprehensive Agent Data Collection and Training Pipeline for Large Language Model
[ad_1]
Integrating Large Language Models (LLMs) in autonomous agents promises to revolutionize how we approach complex tasks, from conversational AI to code generation. A significant challenge lies at the core of advancing independent agents: data’s vast and varied nature. Diverse sources bring forth a plethora of formats, complicating the task of training agents efficiently and effectively. The heterogeneity of data not only poses a roadblock in terms of compatibility but also affects the consistency and quality of agent training.
Existing methodologies, while commendable, often need to address the multifaceted challenges presented by this data diversity. Traditional data integration and agent training approaches are met with limitations, highlighting the need for a more cohesive and flexible solution.

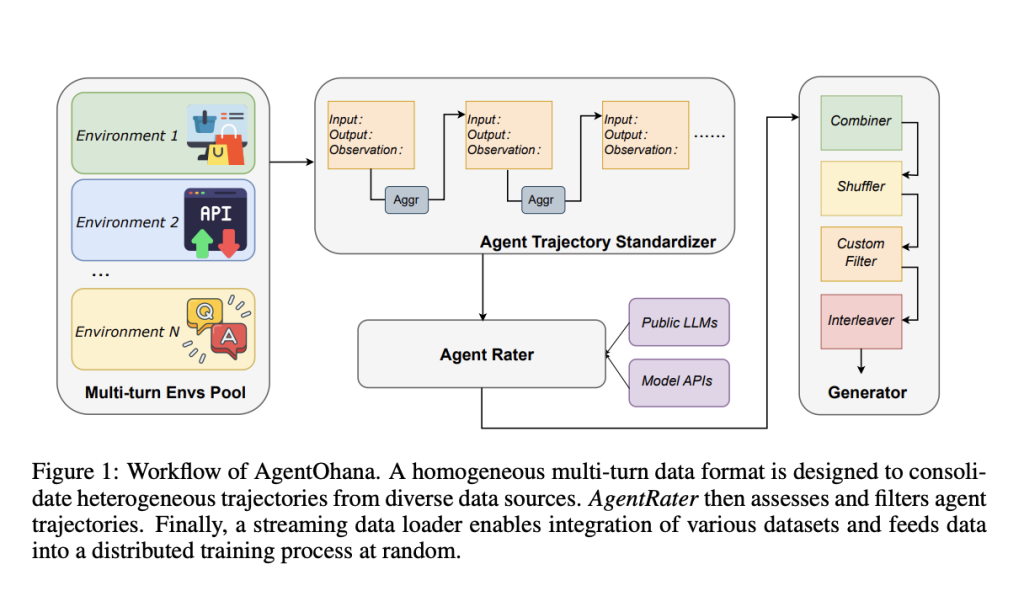
A team of researchers from Salesforce Research, USA, has introduced AgentOhana. This comprehensive solution addresses the challenges of harnessing the potential of LLMs for agent-based tasks. It standardizes and unifies agent trajectories from diverse data sources into a consistent format, optimizing the dataset for agent training. Creating AgentOhana is a significant step in consolidating multi-turn LLM agent trajectory data.
AgentOhana employs a training pipeline that maintains equilibrium across data sources and preserves independent randomness during dataset partitioning and model training. The data collection undergoes a meticulous filtering process to ensure high-quality trajectories, enhancing the overall quality and reliability of the collected data. AgentOhana provides a granular view of agent interactions, decision-making processes, and results, enabling a more nuanced understanding and improvement of model performance. It incorporates agent data from ten distinct environments, facilitating a broad spectrum of research opportunities. It also includes the development of XLAM-v0.1, a large action model tailored for AI agents, demonstrating exceptional performance.

The efficacy of AgentOhana and XLAM-v0.1 is evident in their performance across various benchmarks, including Webshop, HotpotQA, ToolEval, and MINT-Bench. AgentOhana achieves high accuracy in the Webshop benchmark based on attribute overlapping between purchased and ground-truth items. For the HotpotQA benchmark, AgentOhana achieves high accuracy in multi-hop question-answering tasks that require logical reasoning across Wikipedia passages. These results underscore the effectiveness of AgentOhana’s approach, offering a glimpse into the future of autonomous agent development.
In conclusion, AgentOhana represents a significant stride towards overcoming the challenges of data heterogeneity in training autonomous agents. By providing a unified data and training pipeline, this platform enhances the efficiency and effectiveness of agent learning and opens new avenues for research and development in artificial intelligence. The contributions of AgentOhana to the advancement of autonomous agents underscore the potential of integrated solutions in harnessing the full capabilities of Large Language Models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram ChannelYou may also like our FREE AI Courses….
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
 Join the Fastest Growing AI Research Newsletter Read by Researchers from Google + NVIDIA + Meta + Stanford + MIT + Microsoft and many others…
Join the Fastest Growing AI Research Newsletter Read by Researchers from Google + NVIDIA + Meta + Stanford + MIT + Microsoft and many others…[ad_2]
Source link

 Live Breaking: নির্বিকার দিঘা অথরিটি। .. মৃত ডলফিন এ দূষণ ছড়াচ্ছে
Live Breaking: নির্বিকার দিঘা অথরিটি। .. মৃত ডলফিন এ দূষণ ছড়াচ্ছে 




